
Des données de sécurité complètes sont indispensables pour une gestion effective de la sécurité routière. Elles sont essentielles à une approche fondée sur le retour d’expérience, en particulier pour produire : des stratégies fondées sur les résultats, des programmes et des projets d’actions, l’identification des principaux types d’accidents et leurs emplacements, le diagnostic des causes des blessures graves et mortelles dans les accidents de la route, la sélection des traitements, et le suivi et l’évaluation des progrès.
L’établissement des bases de données et leur mise à jour sont explicitement identifiés comme faisant partie du Plan mondial pour la Décennie d’Action, dont le Pilier 1 (Gestion de la Sécurité routière) souligne l’importance de cette activité (CNUSR, 2011).
Les données sur les accidents sont certes des données cruciales de sécurité et constituent une précieuse source d’information pour la gestion de la sécurité routière, mais elles ne sont pas les seules données nécessaires à cette fin. D’autres informations doivent les compléter, telles que : l’inventaire des routes, les données d’enquêtes sur les comportements critiques, des données sur les sanctions policières, le réseau routier et la sécurité du parc de véhicules, ainsi que sur la qualité du système médical d’interventions d’urgence.
Ces données sont importantes pour fournir des mesures intermédiaires de sécurité. Dans les PRFIs, où les bases de données sur les blessures par accident de la route ne sont pas complètes ou opérationnelles, les données obtenues à partir d’enquêtes sont essentielles pour mesurer et cibler des problèmes de sécurité. L’examen de la capacité de gestion dans ces pays indique que cette dernière est insuffisante. De ce fait, il est nécessaire de renforcer leurs compétences afin d’améliorer le recueil, le stockage, l’analyse et le partage des données de sécurité routière.
Ce chapitre présente une information sur les types de données requis pour peupler les bases de données de même que sur le recueil et l’utilisation de celles-ci. Il comporte aussi des conseils sur le croisement des différents types de données, permettant de gérer la sécurité routière plus efficacement.
Des exemples d’utilisation de ces données sont présentés dans l’ensemble du Manuel, en particulier sur :
Une grande partie du présent chapitre examine la gestion des données de sécurité au niveau du réseau (par exemple, pour tout le pays). Toutefois, il est reconnu que l’établissement d’une source nationale de données, bien qu’essentielle, peut se trouver hors de portée pour certains pays. Dans de tels cas, et au minimum, l’information contenue dans ce chapitre peut être utilisée pour initier le recueil de données sur les routes à haut risque, notamment à partir de projets de démonstration dans des corridors et zones sélectionnés (voir Chapitre 6).
Pour une gestion efficace de la sécurité routière, et ainsi que déjà signalé ailleurs dans ce Manuel, l’attention doit se concentrer sur l’élimination des décès et des blessures graves (définis au chapitre 5.2). Le recueil de données devrait donc donner la plus haute priorité à l’information sur les blessures graves et mortelles, les types d’accidents (tels qu’identifiés au chapitre 4), et les facteurs causant ces blessures. Il existe aussi des utilisations importantes des données sur les blessures mineures et même sur les accidents sans blessure ; l’information correspondante devrait donc être recueillie autant que possible.
Les pays doivent commencer par évaluer l’information sur la sécurité qu’ils collectent déjà, déterminer quelles sont les parties prenantes principales (collecteurs et utilisateurs), comment les données sont utilisées, et quelle information supplémentaire est nécessaire (chapitres 5.2 et 5.3).
Il leur faut ensuite initier le recueil des données de « résultats finaux » sur les blessures (en particulier les blessures graves et mortelles), qui peuvent dans un premier temps être obtenues pour les routes et corridors à haut risque (habituellement les routes nationales à fort volume de circulation ; chapitre 5.3).
Ensuite vient le recueil des données sur les « résultats intermédiaires » ou de l’information sur les indicateurs de résultats (voir chapitre 5.2). L’information sur les routes et leurs abords est de haute priorité, et peut être utilisée pour identifier des problèmes et des solutions, y compris en l’absence de données détaillées sur les accidents (chapitre 5.4). D’autres données intermédiaires concernent le respect des règles de circulation (telles que les taux d’excès de vitesse, d’alcoolémie et de port du casque ; chapitre 5.4). Elles peuvent aussi permettre d’identifier des problèmes et des solutions, et être utilisées dans la gestion des résultats de la sécurité routière.
Les données sur la sécurité ont des utilisations et des utilisateurs variés. Comme il est indiqué plus bas au chapitre 5.6, ces données peuvent être utilisées par les décideurs politiques, les ingénieurs routiers, la police, le secteur de la santé, la communauté des chercheurs, les compagnies d’assurance, les tribunaux, les fabricants de véhicules, et d’autres. Des données résumées (en particulier sur les décès par accident) sont disponibles dans la plupart des pays, mais une information plus détaillée est nécessaire pour répondre aux besoins de ces utilisateurs. Sans le recueil de ces données, il n’est pas possible de suivre une approche pour la gestion de la sécurité routière fondée sur le retour d’expérience.
L’OMS (2010) examine l’utilisation des données pour une approche de santé publique à la sécurité routière. Ce document contient une description complète des systèmes de données, y compris leur place dans la gestion de la sécurité routière, leur établissement et leur utilisation. C’est une lecture essentielle sur le sujet, en particulier pour les praticiens des PRFIs qui souhaitent établir ou améliorer un système de données. Ce document suggère une approche cyclique à :
Ce processus est ensuite répété.
L’OMS (2010) offre aussi des conseils sur la relation à faire entre les données de sécurité routière et une gestion efficace de celle-ci (Graphique 5.1) ; ces conseils fournissent un cadre pour le recueil et l’utilisation de ces données. Le document de l’OMS est très clair sur le fait que les seules données sur les accidents ne sont pas suffisantes pour gérer la sécurité, mais qu’elles doivent plutôt être utilisées en combinaison avec d’autres sources d’information. Cette information supplémentaire est nécessaire pour mieux interpréter les risques, aidant ainsi à assurer le suivi et l’obtention des résultats.
; GRSF, (2009).")
Graphique 5.1 : les besoins de données pour la gestion de la sécurité routière
Le Graphique 5.1 et l’Encadré 5.1 (ainsi que OMS (2010) et FMSR (2009 et 2013)), montrent que les résultats désirés en matière de gestion de la sécurité routière sont exprimés en objectifs et cibles, et s’obtiennent à des niveaux différents mais associés. Ces derniers comprennent les résultats institutionnels, découlant des politiques, programmes et projets mis en œuvre, qui affectent une variété de résultats intermédiaires, dans le but ultime de réduire les blessures graves et mortelles, selon le Système Sûr.
Résultats finaux : Les indicateurs de résultats peuvent comprendre : le nombre de décès et de blessures graves, les accidents liés à certains usagers (par exemple, les piétons ou les motocyclistes) ou à certaines circonstances (par exemple, aux carrefours, chocs frontaux), les taux d’accidents (par exemple, nombre d’accidents par population, par nombre de véhicules immatriculés, ou selon la distance parcourue).
Résultats intermédiaires : Les indicateurs de résultats de la sécurité peuvent inclure des mesures du comportement des usagers, telles que : la vitesse moyenne, l’alcoolémie, les taux de port de la ceinture de sécurité ou du casque, l’information des enquêtes sur l’attitude des usagers, les classifications de la sécurité des véhicules, des mesures de l’infrastructure, comprenant les classifications de sécurité de la route, le % de routes à fort trafic et grande vitesse divisées par une barrière médiane, le % de routes où les piétons sont présents et disposent d’allées piétonnières adéquates et les indicateurs post-accident tels que les temps de réponse des véhicules d’urgence.
Produits : Les indicateurs de processus/mise en œuvre peuvent inclure : les politiques, plans et programmes qui ont été mis en œuvre, et les détails de cette mise en œuvre (par exemple, campagnes de promotion du port de la ceinture de sécurité, heures supplémentaires de contrôles routiers de la vitesse, investissement en infrastructure routière sûre, nombre de nouvelles ambulances).
Par exemple, l’analyse des données peut avoir identifié la vitesse des véhicules comme un facteur de risque. Une politique visant à améliorer le respect des limites de vitesse, nécessitera d’amplifier les contrôles de police de la vitesse. Les résultats de cette action témoigneront de l’effet de cette augmentation des contrôles de police. Une mesure de résultats intermédiaires pourrait être le pourcentage de conducteurs en excès de vitesse en des emplacements sélectionnés. Une réduction du nombre des contrevenants aux limites de vitesse aiderait à déterminer si l’action a l’effet désiré. Les indicateurs de résultats finaux seraient le nombre total des décès et des blessures graves (dans l’idéal ceux liés à un excès de vitesse), afin d’établir le bénéfice ultime de l’action.
Les données sur les accidents sont évidemment une source principale d’information sur la sécurité routière, mais d’autres sources de données jouent également un rôle très important. Il y a une prise de conscience croissante de l’utilité, pour la sécurité routière, des données sur le patrimoine routier (dont les caractéristiques de conception des routes). Dans de nombreux cas, il est possible que l’information ait déjà été collectée par ailleurs et soit disponible. Comme indiqué plus loin dans ce chapitre, de nombreux pays ne disposent pas d’informations exactes sur les accidents, et jusqu’à ce qu’ils y parviennent, l’information sur les caractéristiques géométriques des routes et sur les comportements critiques de sécurité fournira un important moyen pour identifier les zones à haut risque et la manière de les traiter.
Souvent, différentes sources d’informations seront disponibles sur des sujets similaires, et si de multiples sources d’information peuvent être utiles pour aider à mieux comprendre les questions de sécurité routière, elles peuvent aussi amener la confusion si elles fournissent des informations contradictoires. Les différences peuvent provenir d’inexactitudes dans les données, ou de variations dans la manière de collecter les données (chapitre 5.5). S’il existe un risque potentiel de confusion du fait de sources multiples, il est important de sélectionner une « seule source de vérité » à laquelle on se réfèrera en fin de compte pour la prise de décision. Les raisons pour la sélection de cette source d’information devront être pleinement justifiées.
Ce Manuel utilise différents termes pour distinguer différents degrés de gravité des blessures. L’Encadré 5.2 fournit leur définition.
Blessure mortelle : toute blessure causant le décès immédiat ou dans les 30 jours suivant un accident de la circulation, à l’exclusion des suicides.
Blessure grave : blessure qui requiert l’admission à l’hôpital pour au moins 24 heures ou l’attention d’un spécialiste, telle que fractures, concussions, chocs sévères ou lacérations profondes. Certains pays ont adopté la Liste Type des Blessures (Maximum Abbreviated Injury Scale, MAIS), et suggéré que les blessures graves soient définies comme MAIS3+.
Blessure mineure ou autre : blessure qui ne requiert que peu ou pas d’attention médicale (par exemple foulures, hématomes, coupures ou abrasions superficielles).
Dommages matériels/sans blessures : dommage aux véhicules seulement, sans blessure aux occupants/usagers.
Source : OMS, (2010).
Ce chapitre présente des conseils pour l’établissement et la mise à jour des bases de données sur les accidents de la circulation ; des informations plus détaillées sur le sujet peuvent être obtenues auprès de l’OMS (2010). Les informations sur le recueil et l’utilisation d’autres sources de données sont présentées dans les chapitres suivants ; ci-dessous se trouve un résumé des questions clés.
Il est établi qu’aucune base de données sur les blessures par accident de la route ne fournira en elle-même assez d’information pour dresser un tableau complet des blessures par accident de la route ou pour permettre de pleinement comprendre ce qui a conduit aux blessures (IRTAD, 2011). Certains des pays ayant amélioré leurs résultats en matière de sécurité routière utilisent des données recueillies par la police ainsi que par le secteur de la santé.
Généralement, les données nationales sur les accidents sont recueillies par la police, et l’OMS (2013) rapporte que plus de 70% des pays utilisent les données de la police comme leur source principale. Elles sont ensuite saisies dans les bases de données sur les accidents pour en faire l’analyse et les rapports annuels. Dans certaines circonstances, les données sont recueillies auprès des hôpitaux, ou à partir de ces deux sources. L’utilisation des données du secteur de la santé est nécessaire pour une classification des blessures au niveau national, pour compléter les données de la police, et définir les « blessures graves ». L’IRTAD (2011) recommande que les données de la police demeurent la source principale pour les statistiques sur les accidents de la route, mais qu’elles soient complétées par les données des hôpitaux pour des raisons de qualité, et pour identifier les niveaux de sous-déclaration (paragraphe 2.4). De plus, obtenir des données approfondies à partir de la recherche sur les blessures par accident de la route est nécessaire pour parvenir à des conclusions significatives sur les causes des accidents et des blessures.
La police est évidemment bien placée pour collecter l’information sur les accidents, parce qu’elle est très souvent appelée sur les lieux de l’accident. Alternativement, elle peut recevoir des informations sur l’accident après celui-ci. La présence sur le lieu de l’accident permet le recueil d’informations détaillées qui seront utiles pour identifier les causes de l’accident et les solutions possibles.
Généralement, un rapport d’accident est rempli (traditionnellement c’est un formulaire sur papier, mais depuis peu des systèmes informatisés ont fait leur apparition), pour recueillir une information détaillée sur l’accident. Les variables critiques typiquement recueillies comprennent :
L’OMS (2010) propose des exemples de formulaires de rapport d’accident, comportant les détails qui devraient être recueillis au minimum. Les conseils contenus dans le document de l’OMS sont inspirés de la Base de Données européenne commune sur les Accidents (European Common Accident Database, CARE). Certains pays ont développé leurs propres critères minimum. Par exemple, les USA ont établi un Modèle Uniforme de Critères Minimum sur les Accidents (Model Minimum Uniform Crash Criteria, pour plus d’information, voir la page Internet correspondante http://www.mmucc.us/).
Un équilibre doit être trouvé entre le recueil des données requises, et le temps passé à accomplir cette tâche. Si le fardeau est trop lourd pour la police, il est peu probable que le formulaire d’accident soit rempli. La police est une partie prenante cruciale pour l’établissement, la mise à jour et l’utilisation des données sur les accidents, et devrait être incluse dans chaque étape du processus.
Les données des hôpitaux sont utilisées pour identifier les niveaux de sous-déclaration ou pour obtenir une meilleure information sur les blessures, en particulier lorsque les données des rapports de police ne sont pas disponibles ou adéquates. L’IRTAD (2011) suggère que les données des hôpitaux devraient être recueillies précisément en raison de la sous-déclaration des accidents de la circulation, et qu’elles sont la seconde meilleure source d’information sur les statistiques d’accidents.
Encouragées par l’OMS et d’autres institutions, les autorités médicales ont établi des systèmes internationaux d’enregistrement qui incluent les blessures par accident de la route. Les systèmes de codage Classification Internationale des Maladies et des Problèmes de Santé Associés (International Classification of Diseases and Related Health Problems, ICD) et la Liste Type des Blessures (Abbreviated Injury Scale, AIS) en particulier sont largement utilisés. L’IRTAD (2011) recommande le développement d’une définition acceptée au niveau international des « blessures graves », et l’utilisation de la Liste Type Maximale des Blessures (MAIS) comme base pour la définition de la gravité des blessures dues à des accidents de la route. Cette échelle se fonde sur la gravité maximale des blessures à n’importe laquelle de neufs parties du corps humain ; une note de 3 points ou plus pour une ou plusieurs régions du corps (MAIS3+) est recommandée comme définissant à partir de quand une blessure est considérée comme grave.
Il existe des exemples de recueil de données dans les hôpitaux permettant une analyse détaillée, tels que l’étude de cas thaïlandaise ci-dessous (Encadré 5.3).
Le problème : bien qu’une information sur les accidents soit disponible à partir d’autres sources, elle n’était pas suffisante pour gérer de manière adéquate la sécurité routière dans la province de Khon Kaen en Thaïlande. Une source alternative d’information existait à partir de données d’hôpitaux, mais elle ne fournissait pas d’information sur le lieu des accidents.
La solution : l’hôpital régional de Khon Kaen au nord-est de la Thaïlande possédait son propre Registre des Blessures depuis 1989. Une information supplémentaire a été ajoutée à cette base de données en utilisant un formulaire de « Déclaration d’Accident », comprenant l’information sur les circonstances de l’accident, les facteurs pouvant y avoir contribué, et une description du lieu de l’accident. Le développement de l’analyse spatiale SIG des données des hôpitaux a inclus la révision du formulaire de rapport d’accident et de ceux de surveillance des blessures. Le premier a été modifié pour exclure l’information sur les dommages matériels parce qu’elle exigeait des inspections du site, et le second a été modifié pour refléter toute l’information sur la personne blessée (par exemple, le port de la ceinture de sécurité, etc.).
En plus des données de base sur les accidents, les lieux ont été encodés spatialement grâce à un Système d’Information Géographique (SIG). Un lien sur le SIG a été développé pour obtenir les caractéristiques de géométrie des routes. L’utilisation de la technique de cartographie SIG a permis de visualiser les caractéristiques des emplacements des accidents (par exemple, carrefours, passages à niveau et giratoires).
Les résultats : l’ajout de cette information a permis une analyse détaillée des données sur les accidents, y compris l’identification des zones/emplacements à haut risque. Plusieurs études détaillées sur des questions spécifiques à la sécurité routière ont été entreprises dans les dernières années sur la base de cette riche source d’information.
Pour plus de détails, voir Ruengsorn et al, (2001).
L’Encadré 5.4 offre un autre exemple, celui de l’intégration en Égypte de données provenant de différentes sources, et de leur utilisation par plusieurs parties prenantes.
Le problème : le besoin d’un système de données sur les accidents centralisé et exact.
La solution : le système national de gestion des accidents est conçu pour être à la fois un nouveau système pour la recherche et l’analyse des données sur les accidents de la route, et un espace partagé pour toutes les parties répondant à différents types d’accidents de la route, telles que les services médicaux d’urgence, les forces de police, les pompiers, le personnel des hôpitaux, et les autorités routières. La passation de marché a démarré durant le premier trimestre de 2010, et incluait l’acquisition d’équipements et de logiciels, de terminaux mobiles avec GPS pour être utilisés sur les lieux des accidents afin de déterminer l’emplacement exact de l’accident, le documenter, établir la déclaration d’accident par les officiers de police et les ambulanciers.
Ce nouveau système mettra en œuvre un processus unifié pour la recherche et l’établissement de statistiques sur les accidents, pour harmoniser les données des différentes sources, et fournir aux chercheurs en sécurité routière les données nécessaires. Les terminaux portables pour l’enregistrement des accidents contiendront des formulaires de déclaration d’accident sous forme de tableaux à choix multiples, faciles à remplir sur le lieu de l’accident et organisés de telle manière que les données personnelles des accidentés ne pourront être fournies qu’aux tribunaux, aux assureurs et aux hôpitaux.
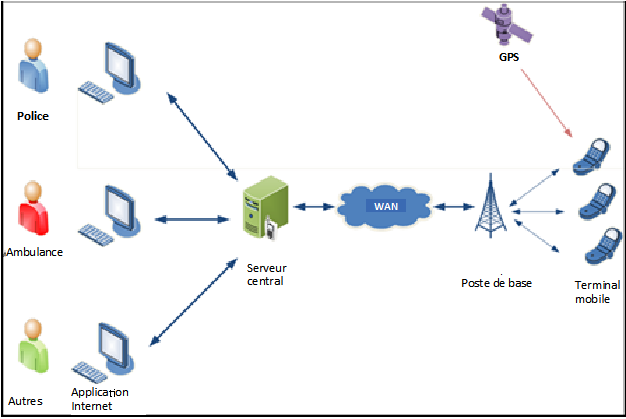
Les résultats : le principal résultat a été la réduction significative de la sous-déclaration, et une étroite coopération entre les principales parties prenantes. De plus, un système détaillé d’information permettant la recherche sur les accidents est désormais en place.
Un enseignement clé de cette action est que la gestion digitale des données GPS sur les accidents est essentielle pour une politique de sécurité routière autant que pour la gestion de la sécurité de l’infrastructure. Le système de gestion des données doit aussi outrepasser les restrictions policières sur l’accès aux données sur les accidents.
Source: Hans-Joachim Vollpracht, World Road Association (AIPCR)

Les données d’état civil peuvent être une source d’information sur les décès par accident de la route. Cette information provient des certificats de décès remplis par les médecins et précise les causes du décès. L’OMS (2010) signale qu’environ 40% de ses pays membres collectent des données d’état civil pour le suivi des décès dus à des accidents de la circulation. L’OMS et d’autres organisations ont institué un système international d’enregistrement qui inclut les blessés des accidents de la route.
D’autres sources de données sur les accidents peuvent provenir des services d’urgences, des services de dépannage, des compagnies d’assurances, de membres du public, etc. Cependant, il est important de reconnaître que la qualité et l’étendue de ces informations peuvent être limitées, par rapport aux données rapportées par la police et les hôpitaux.
Avant d’établir un nouveau système (ou d’améliorer un système existant) de données sur les accidents de la route, il est recommandé d’effectuer une évaluation de la situation (OMS, 2010). Ceci implique :
Ces mêmes étapes sont aussi requises pour établir ou améliorer les données autres que celles des accidents (voir chapitre 5.4).
L’analyse des parties prenantes implique l’identification des organisations et des individus qui ont (ou devraient avoir) un rôle à jouer dans le recueil et l’utilisation des données de sécurité routière. Les principales parties prenantes comprennent la police, les agences de transport et les départements de la santé, et probablement beaucoup d’autres.
Une évaluation des sources de données est nécessaire pour déterminer quelles informations sont déjà recueillies, et leur qualité. Dans de nombreux pays, la qualité des données est souvent un problème d’importance.
L’évaluation des utilisateurs finaux consiste à comprendre quels seront les principaux utilisateurs et comment ils utiliseront les données. Ceci aidera à accroître l’utilité des données.
L’analyse environnementale se réfère à la compréhension de l’environnement politique et des partenariats critiques nécessaires pour une collecte, une analyse et une utilisation fructueuses des données. Sans cette compréhension et une collaboration appropriée, il est probable que le recueil et l’utilisation des données seront sévèrement entravés. Nombreux sont les exemples où d’onéreux systèmes de données sur les accidents ont été établis, mais où la saisie des données ne s’est pas faite, en raison d’une communication inadéquate et d’une collaboration déficiente.
Après l’évaluation de la situation, le processus recommandé pour établir un système de données sur les accidents est :
Le lieu de l’accident est un élément essentiel dans le recueil et l’analyse des données, en particulier pour les ingénieurs routiers. Sans cette information, il n’est pas possible de déterminer les emplacements à traiter dans le futur. Si le lieu de l’accident est connu (grâce aux rapports de police ou à d’autres sources), il est possible d’associer ces données d’accidents avec celles sur l’infrastructure ou d’autres sources (chapitre 5.6). Cette information peut être utile pour identifier d’autres aspects de l’infrastructure qui peuvent avoir contribué à l’accident.
Il existe plusieurs méthodes pour déterminer précisément le lieu d’un accident, telles que l’utilisation du GPS, la référence à un point repère local (par exemple, un système lien-nœud) ou la référence à une borne kilométrique (un système de référence linéaire).
Historiquement, les données sur les accidents étaient conservées dans des systèmes de classement de documents papier. Aujourd’hui, elles sont stockées dans des bases de données informatisées, ce qui permet une analyse relativement facile et est particulièrement utile pour identifier les tendances, les zones et sites à haut risque, les principaux types d’accident, etc. Il existe des logiciels spécialisés pour cela. Au minimum un tel logiciel doit être capable de :
Les systèmes de données sur les accidents sont désormais très évolués, avec de nouvelles fonctions permettant une analyse plus rapide et plus utile. L’OMS (2010) et Turner et Hore-Lacy (2010) ont produit une liste de fonctions désirables d’un système de données sur les accidents, dont :
L’étude de cas cambodgienne ci-dessous fournit un exemple de mise en œuvre réussie d’un système de données sur les accidents (Encadré 5.5).
Le problème : le système de base de données du Cambodge ne permettait pas de gérer de manière adéquate les résultats en matière de sécurité routière. Depuis 2002, trois ministères différents avaient participé au recueil de données (Travaux Publics et Transports, Intérieur et Santé). Les trois bases de données développées par ces trois ministères fournissaient certes un certain niveau d’information sur la sécurité routière dans le pays, mais le besoin d’amélioration était évident parce que :
La solution : en 2004, la fondation Handicap International Belgique et la Croix-Rouge cambodgienne ont proposé un nouveau système, fondé sur un formulaire de collecte uniformisé et plus détaillé. L’objectif était d’obtenir une information exacte, continue et complète sur les accidents de la route et leurs victimes, afin d’accroître la compréhension de la situation au regard de la sécurité routière, de planifier les réponses appropriées, et d’évaluer l’impact des initiatives. Le système a d’abord été testé dans la capitale, Phnom Penh en 2004, comme projet pilote, puis son succès a conduit à son extension à toutes les provinces en 2006.
Handicap International (HI), une organisation d’aide internationale, a joué un rôle primordial dans le développement et la mise en œuvre du système RCVIS, et a été dans un premier temps chargée de la supervision du système tout entier. HI a ensuite progressivement confié le travail au gouvernement cambodgien, et transmis les responsabilités de collecte des données aux Ministères de la Santé et de l’Intérieur en 2008-2009, pour enfin transférer toute la supervision du système au Comité national sur la Sécurité Routière en 2010.
Le système combine des données de la police et du secteur de la santé. Le diagramme ci-dessous montre sa structure (depuis 2009).
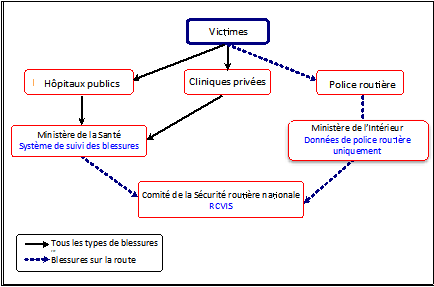
Les résultats : les deux sources de données du Cambodge ont permis au système de couvrir plus d’éléments d’information détaillée sur les accidents (données de la police) et sur les décès (données des hôpitaux), ce qui a permis des niveaux plus élevés de déclaration. Plusieurs facteurs ont contribué au succès du RCVIS. L’un d’entre eux a été le développement simultané des deux formulaires du système : l’un pour la police routière, et l’autre pour le secteur de la santé. Ceci a permis une compréhension commune des aspects techniques du système, qui comportait des questions communes (variables) aux deux formulaires. Tous les acteurs principaux ont été impliqués dès le stade de développement, ce qui signifie qu’ils ont tous participé à la création des parties communes aux deux formulaires et approuvé leur contenu.
Ensuite, le pouvoir a été donné au Ministère des Travaux Publics et des Transports de jouer un rôle de coordination, avec un clair entendement dès le début que les deux sources de données devraient être combinées. Le Ministère a bénéficié de soutien pour organiser des réunions, diriger les débats, assurer la présidence des ateliers de travail annuels du RCVIS, et devenir l’un des co-auteurs des publications du RCVIS, etc.
Enfin, les données et les conclusions de la phase de projet pilote ont aidé tous les acteurs à comprendre les problèmes et à affiner le processus. Il est clair que les rapports sur la phase pilote ont été très appréciés par les principales parties prenantes du gouvernement, les médias et les membres des groupes de travail.
Cependant, en dépit de grandes avancées réalisées grâce à lui, le système RCVIS présente toujours certains problèmes. La déclaration des données n’est pas cohérente, en particulier celle des services de santé. Pour aborder la question de non-déclaration, il est recommandé que le Comité national sur la Sécurité Routière et le Ministère de la Santé prennent des mesures telles que :
Source: Chariya Ear, Handicap International, Cambodge.
Le système suédois Strada est une base de données unique qui intègre les données de la police et des hôpitaux. Ici, il est important de reconnaître que si cette caractéristique fournit des informations supplémentaires, elle coûte aussi plus cher. L’Encadré 5.6 ci-dessous offre plus de détails.
Le problème : le manque d’information fiable sur les accidents, y compris l’information sur les conséquences des blessures.
La solution : en octobre 1996, l’Administration des Routes de la Suède a été chargée par le gouvernement suédois de créer un nouveau système d’information couvrant les accidents et les blessures sur tout le réseau routier. Cela s’est fait en coopération avec la police nationale suédoise, le Conseil national suédois sur la Santé et le Bien-Être, l’Institut suédois pour l’Analyse des Communications et des Transports, les Statistiques de Suède, et l’Association suédoise des Régions et des Autorités locales.
Le système Strada se fonde sur les informations rapportées par deux sources : la police et les hôpitaux. Tous les districts de police renseignent Strada à l’échelle nationale depuis 2003. Strada reçoit aussi des informations de la part d’un nombre croissant d’hôpitaux, et l’inclusion de ces données rend cette méthode très différente des méthodes antérieures d’enregistrement des accidents et des blessures survenus dans le réseau routier.
Les résultats : en réunissant les données de deux sources, la police et les hôpitaux, Strada fournit une information plus détaillée, accroissant ainsi les connaissances sur les accidents et les blessures par accident de la route. L’inclusion des données des hôpitaux réduit la sous-déclaration, car la police n’est pas toujours informée de certains accidents (principalement ceux impliquant des usagers non protégés, tels que piétons, cyclistes, et conducteurs de vélomoteurs). De plus, les rapports des hôpitaux précisent les diagnostics, ce qui enrichit les connaissances sur les blessures et leur degré de gravité.
Les données sont saisies par la police locale et les hôpitaux dans le système Strada, où les coïncidences sont immédiatement comparées.
Jusqu’à maintenant, le niveau d’exactitude de la comparaison des données est très élevé. « Comparaison des données » signifie que les données ont été saisies à la fois par la police et les hôpitaux. Une description plus complète des circonstances de l’accident et des blessures est obtenue à partir des données comparées, ce qui permet une information plus exacte sur les véritables problèmes de la sécurité routière, laquelle à son tour facilite la planification et la priorisation de mesures en la matière.
En 2013, la police a enregistré 15 000 accidents dont 20 600 personnes blessées. Celles-ci ont été comparées avec 32 700 personnes ayant recherché un traitement à l’hôpital, dont 9 800 étaient connues des deux sources. Ceci signifie que 48% des blessures connues par la police l’étaient aussi par les hôpitaux, et que 30% de celles enregistrées par les hôpitaux l’étaient aussi par la police. La conclusion de cette comparaison est que le taux de déclaration par la police est loin de l’exhaustivité.
Étant donné que certains hôpitaux ne rapportent pas encore à Strada, les statistiques officielles existantes se fondent exclusivement sur les accidents rapportés par la police. L’information dérivée des hôpitaux est montrée dans un supplément qui contient des statistiques médicales.
Certains pays ont entrepris des études approfondies sur les accidents graves, afin de mieux comprendre les facteurs de causalité des accidents et de déterminer les solutions possibles. Ces études portent, typiquement, sur un échantillon d’accidents de gravité élevée. Par exemple, au Royaume-Uni, le projet « On the Spot » a recueilli une information détaillée et de bonne qualité pour deux régions. Pour chaque accident, plus de 2 000 variables ont été recueillies à partir d’une recherche sur le lieu de l’accident peu après celui-ci, et du suivi effectué auprès des services médicaux et du gouvernement local. L’information a été analysée pour donner un aperçu de l’implication humaine, de la conception du véhicule, et celle de la route dans les facteurs ayant causé l’accident et les blessures. Mansfield et al (2008) ont effectué l’analyse initiale d’environ 2 000 accidents de ce projet. Une telle recherche peut fournir beaucoup plus de détails que ce qui est normalement disponible à partir d’un rapport d’accident, avec un degré plus élevé de fiabilité.
Des exemples similaires existent dans plusieurs autres pays, comme les États-Unis, l’Allemagne, la France, la Malaisie, l’Inde et l’Australie. Certains de ces programmes sont en place depuis des années, et ont apporté une grande quantité d’information précieuse. L’un des principaux produits du projet européen DaCoTa (qui a recueilli et analysé des données de pays européens sur divers aspects de la sécurité routière) sont des recommandations sur le recueil de ces données, ainsi que l’uniformisation des procédures (Thomas et al, 2013). Un réseau pan-européeen de recherche approfondie sur les accidents a été établi, et des outils tels qu’un manuel en ligne sur la recherche approfondie sur les accidents de la route ont été développés (voir http://dacota-investigation-manual.eu ).
Les États-Unis ont créé le Deuxième Programme Stratégique de Recherche sur les Routes, SHRP2 (Strategic Highway Research Program), qui comporte peut-être la base de données la plus exhaustive sur les facteurs avant et durant les accidents, et sur les quasi-accidents. Cette information comprend des données de la base NDS (Naturalistic Driving Study, étude sur la conduite en situation réelle), obtenues, auprès de 2 300 conducteurs, dans des conditions normales de conduite, grâce à des équipements installés à l’intérieur de leur véhicule.
La quantité massive de données recueillies par la NDS est complétée par la base de données sur l’information routière (RID, Roadway Information Database), qui inclut une information exhaustive sur l’infrastructure routière dans les zones étudiées, ainsi que d’autres données pertinentes (y compris sur les accidents). Cette base de données d’intérêt mondial doit servir pour des recherches sur le comportement et la performance des conducteurs. La page Internet suivante offre plus d’information : www.trb.org/StrategicHighwayResearchProgram2SHRP2/Pages/Safety_153.aspx .
Partager les données provenant de différentes sources est indispensable pour une collecte, une analyse et une intégration exhaustives. Le partage des données, en particulier entre la police et les autorités routières, est essentiel pour une bonne gestion de la sécurité routière.
Il est cependant important de noter que certaines organisations pourraient être réticentes à partager certaines données, en particulier les identifiants personnels, du fait des difficultés que cela pose quant à la vie privée et l’anonymat. Une solution est de collecter les données personnelles sur une page séparée du rapport d’accident (par exemple, le nom et l’adresse), qui peut ensuite être enlevée avant d’envoyer les autres pages aux agences partenaires. Dans certains cas, il peut être approprié de définir une politique de confidentialité pour assurer que le problème est traité, ou pour que certaines variables soient supprimées pour empêcher l’identification des personnes.
Les données sur les accidents sont en elles-mêmes une précieuse source d’information sur le risque d’accident, et cette valeur peut augmenter de manière significative si elles sont combinées avec d’autres données. Le chapitre suivant examine certaines des autres sources de données, et le chapitre 5.6 indique comment combiner ces sources.
Les données sur les accidents sont généralement considérées comme une source essentielle d’information pour évaluer et traiter le risque. Cependant, dans certains pays et plus particulièrement dans les PRFI, elles peuvent ne pas être fiables, ou même disponibles, et dans ce cas, des enquêtes supplémentaires et d’autres sources de données peuvent constituer la seule source disponible de données fiables sur la sécurité routière. Comme déjà indiqué au chapitre 5.2, cette information supplémentaire (indicateurs des résultats de la sécurité) est également importante pour la gestion de la sécurité routière car elle permet d’évaluer différents programmes, projets et politiques afin d’identifier leur effet sur les résultats. Ceci se fait à travers le recueil et l’évaluation de détails relatifs aux interventions mises en œuvre, et aux résultats intermédiaires.
Une variété d’autres sources d’information est aussi disponible, comme les données sur la conception et les caractéristiques des routes, les données de circulation, les données d’enquêtes et les données sur l’exposition au risque.
L’inventaire des routes constitue une source d’information majeure qui peut aider à évaluer la sécurité. Parce que l’impact des différents éléments de la route est bien connu, différents éléments ou combinaisons d’éléments peuvent donner une idée sur les problèmes causant des accidents, y compris les principaux types d’accidents résultant en décès ou blessures graves (voir le Chapitre 4). Les données suivantes sont particulièrement utiles :
Les points ci-dessus représentent la liste de base des types pertinents d’éléments de la route, mais de nombreux autres facteurs peuvent avoir une influence sur les résultats de la sécurité routière. Le Programme international d’Évaluation des Routes (iRAP) collecte des données sur presque 70 attributs (voir le site Internet http://www.irap.org/about-irap-3/methodology pour les détails sur ces attributs, le chapitre 10.4.4 sur l’iRAP, et l'Encadré 5.7 pour des exemples sur le recueil de données entreprises au Mexique).
Aux États-Unis, le modèle d’inventaire sur les éléments de la route (MIRE, Model Inventory of Roadway Elements) contient une liste de 202 éléments pouvant être utiles pour la prise de décision en matière de sécurité routière. Voir le site Internet : http://www.mireinfo.org/about.html pour plus d’information.
Le problème : environ 18 000 décès se produisent annuellement dans des accidents de la route sur tout le territoire du Mexique, avec une croissance annuelle moyenne de 1,9%. 25% de ces décès surviennent sur le réseau routier fédéral, qui constitue l’épine dorsale du système national routier et de transport.
La solution : afin d’améliorer la sécurité routière dans le pays, et par là la qualité de vie de ses habitants ainsi que les conditions de sécurité le long des principaux couloirs commerciaux nationaux et internationaux, le Mexique a lancé un projet de prévention visant dans un premier temps à évaluer 46 000 km de routes fédérales en 2012 et 19 000 km de routes collectrices par la suite en 2013. Le lancement du projet a coïncidé avec celui de la Décennie d’Action des Nations Unies, à laquelle le Mexique s’est joint, de sorte que le projet a été conçu à la fois comme une avancée majeure pour améliorer la sécurité routière, et comme le début d’un programme d’évaluation périodique des routes.
Les résultats : au cours de ses deux étapes, le projet a rendu possible la création d’une classification selon un niveau de sécurité pour chaque type d’usager de la route, et d’un plan d’investissement sur 20 ans pour accroître la sécurité. Le résultat de l’évaluation après les deux étapes a été, l’attribution de 1 ou 2 étoiles, vis-à-vis des occupants de véhicules, pour environ 50% des 46 000 premiers kilomètres. Les pourcentages sont encore plus élevés pour les autres usagers plus vulnérables.
Le projet a permis :
L’adoption de cette méthodologie comme programme périodique permettra le suivi de l’efficacité des mesures et des programmes mis en œuvre.
Étude de cas fournie par le Dr Alberto Mendoza, IMT, Mexico.
Les caractéristiques des routes doivent aussi être géo-localisées (dans l’idéal, grâce à un système lié à un SIG) pour permettre une analyse et des liens croisés.
Les données d’inventaire des routes pertinentes pour la sécurité routière peuvent être disponibles ou doivent être recueillies. Une évaluation de la situation devrait être exécutée pour vérifier leur existence (voir chapitre 5.3). Traditionnellement, les données d’inventaire des routes sont utilisées pour les audits ou les inspections (voir Chapitre 10), mais de manière plus récente, des méthodes ont été développées pour quantifier les résultats probables de sécurité routière, sur la base de ces éléments.
Le recueil de ces données peut se fonder sur des approches ad hoc (par exemple, par les inspections périodiques, des plaintes du public, etc.), mais dans l’idéal elles devraient l’être au moyen d’un programme exhaustif exécuté de manière régulière. L’approche la plus commune consiste en l‘extraction de données à partir d’images vidéo, et leur classification ou encodage postérieur par des experts formés à cet effet. Ces données sont ensuite saisies dans une base de données ou un registre du patrimoine routier (Encadré 5.8).
Le recueil des données d’inventaire des routes est extrêmement utile, mais elle doit cependant être effectuée de manière à minimiser les coûts (c’est-à-dire rapidement), et à assurer son exactitude et sa fiabilité.
Plusieurs méthodes de collecte sont disponibles. La technique la plus rudimentaire consiste à enregistrer les données sur des formulaires de collecte en circulant sur les routes. Cette approche ne peut être utilisée que sur des tronçons de route relativement courts, et il peut être difficile de collecter toutes les variables routières pertinentes en se déplaçant à la vitesse du trafic.
Le recueil assistée par ordinateur permet de recueillir des données plus extensives, et peut s’effectuer au moyen d’un ordinateur, d’une « tablette » portable, ou de caméras vidéo. Les données peuvent ensuite être saisies en toute sécurité au bureau. L’utilisation d’une tablette permet d’ajouter l’information à une base de données tout en se déplaçant le long d’une route, typiquement en utilisant la technologie d’écran tactile pour sélectionner les variables routières pertinentes. Différents symboles peuvent être affichés à l’écran pour faciliter une rapide saisie des données. Encore une fois, il est souvent difficile de saisir toutes les variables pertinentes tout en se déplaçant à grande vitesse ou dans des environnements agités ; l’enregistrement vidéo permet d’aider à la saisie et à la vérification ultérieure des données.
Une autre option est l’évaluation des données vidéo à partir d’un ordinateur de bureau. Une ou plusieurs caméras peuvent être utilisées sur tout le réseau d’intérêt. L’utilisation d’une seule caméra permet l’enregistrement d’informations dans une seule direction, vers l’avant, et plusieurs caméras permettent une meilleure collecte d’information sur la route et ses abords. Ces images vidéo sont ensuite utilisées pour encoder les variables d’intérêt, et peuvent être calibrées pour permettre des mesures (telles que la largeur d’une route ou la distance entre la route et des objets fixes situés sur les abords). Ceci permet une collecte plus exacte de l’information, et une identification spatiale exacte.
Les images vidéo sont analysées et peuvent être arrêtées pour l’étude d’environnements plus complexes. L’information obtenue à partir des images est ajoutée à la base de données pour analyse ultérieure. Elle peut être saisie manuellement ou au moyen d’un système de menu déroulant. Typiquement, les données sont recueillies pour de courts tronçons de route (par exemple, un segment de 10 mètres).

Graphique : Peupler une base de données avec des données d’inventaire routier relatives à la sécurité
Les nouvelles technologies en développement aideront à automatiser davantage le recueil des données sur les routes et leurs abords. Par exemple, il est possible de recueillir des informations sur des caractéristiques telles que la largeur de la route, le tracé horizontal et vertical, et l’état de la surface de la route en utilisant des radars (Light Detection and Ranging, LIDAR) et d’autres capteurs dans le véhicule.
Il est important de collecter et d’analyser les données de circulation, et plus particulièrement les volumes de circulation (trafic moyen journalier annuel ou TMJA), parce qu’elles peuvent être utilisées pour générer des taux d’accidents fournissant un bon indicateur des résultats de la sécurité, y compris sur des routes spécifiques, certains types de routes ou même sur des éléments de l’infrastructure. D’autres types de données sur la circulation comprennent :
Les données sur la circulation peuvent être recueillies manuellement ou au moyen de dispositifs automatisés de comptage de la circulation (par exemple, dispositifs de tubes pneumatiques ou de collecte permanente des données installés sur la chaussée).
En plus des données sur la circulation, d’autres sources de données sur l’exposition au risque incluent les données démographiques (population totale, total pour chaque tranche d’âge) pour une zone ou un pays, qui sont habituellement disponibles à partir des données des recensements nationaux. Les données sur l’immatriculation des véhicules sont aussi souvent recueillies et utilisées.
Les enquêtes de comportement collectent des informations sur les impressions des conducteurs, des autres usagers de la route, et des résidents. Elles sont considérées comme une importante source de rétroaction, et peuvent fournir un aperçu du comportement des conducteurs (par exemple, faible niveau de respect des limites de vitesse affichées).
Les informations sur le nombre de contrôles routiers de police (limites de vitesse, alcoolémie, port de la ceinture de sécurité), le nombre d’infractions (excès de vitesse, motocyclistes sans casque), et le nombre de conducteurs punis (amendes, pénalités ou emprisonnements) sont toutes des mesures utiles, qui aideront à évaluer l’impact de nouvelles politiques ou actions pour améliorer les résultats de la sécurité routière.
En plus des sources déjà mentionnées, d’autres informations utiles peuvent être obtenues à partir :
Le chapitre suivant examine d’autres types de données sur le respect des règles de circulation.

Les données sur la circulation et sur le comportement des conducteurs sont rarement disponibles. Il n’existe pas de liste type de données supplémentaires à collecter, et étant donné son coût, tout type de collecte doit être soigneusement planifié, qu’il s’agisse de collecte au niveau national ou visant des sites spécifiques. Les données supplémentaires ne devraient être recueillies que si nécessaire, et ceci de manière économique.
Le chapitre suivant offre une brève description de certaines des données d’enquête les plus communes, des différentes méthodes possibles, ainsi que des références à des documents utiles.
Une étude de vitesse ponctuelle consiste en le recueil d’échantillons de vitesses, sur un site routier spécifique ou sur plusieurs sites, qui seront ensuite analysées pour déterminer la distribution des vitesses des véhicules. Ceci est utile pour :
Les vitesses véhiculaires peuvent être mesurées manuellement (au moyen de radars, de pistolets laser, ou de chronomètres), ou automatiquement (boucles ou tubes). Les méthodes automatiques sont plus adaptées pour les études portant sur de vastes échantillons, parce que les boucles et les tubes peuvent enregistrer plus que les seules vitesses moyennes, comme par exemple les volumes de trafic, les mouvements tournants des véhicules et la mixité de la circulation. Ces composantes sont essentielles pour comprendre les problèmes de sécurité existant sur un site. Le Manuel sur la vitesse du FMSR (GRSF Speed Manual, 2008) et les études du gouvernement du Royaume-Uni (DETR, 2001) constituent des guides détaillés sur la mesure des vitesses et des volumes, et sur la manière de gérer les problèmes de sécurité liés à la vitesse. (Voir l’Encadré 5.9 pour une étude de cas sur le recueil de données sur la vitesse en Inde).
Le problème : des données sur les vitesses des véhicules étaient nécessaires pour une étude portant sur quatre États en Inde.
La solution : des données sur la vitesse et les volumes de circulation et aussi sur les accidents ont été recueillies sur le terrain sur quatre sites-échantillons, à partir des corridors routiers qui faisaient partie du Projet Quatre États 2011 en Inde (2011 Four States Project). L’équipe de recherche a effectué des études sur les vitesses et le volume de circulation pour déterminer la vitesse au 85e-percentile et la densité de la circulation dans ces corridors, par type de véhicule. Les chercheurs ont aussi recueilli les données disponibles de la police sur les accidents, et effectué des recherches sur les sites des accidents pendant presque deux mois, afin de parvenir à une meilleure compréhension des accidents. Ces visites sur le terrain ont été possibles grâce à une étroite collaboration avec les départements de police locale, et aussi à des patrouilles de routine régulières sur ces tronçons routiers.
L’étude a porté sur quatre routes d’États (deux dans l’état de Karnataka, et deux dans l’état de Gujarat), couvrant un total de presque 300 km.
Les résultats : il a été déterminé que les vitesses au 85e-percentile étaient largement au-dessus de la limite de vitesse affichée (qui dans certains cas n’était pas évidente), et de grands écarts de vitesse entre les différents types de véhicules ont été observés. Les voitures montraient des vitesses au 85e-percentile beaucoup plus élevées que celles des autres usagers de la route (deux-roues motorisés, bus et camions). De plus, l’écart entre les vitesses pour un même type de véhicule était aussi très élevé (par exemple, les véhicules motorisés à deux roues se déplaçaient à des vitesses allant de 25 à 80 km/h).
Certaines des principales leçons tirées de cette collecte de données sont que :
En plus de la production de classifications sur le plan de la sécurité, les données sur la vitesse ont conduit à des recommandations pour l’établissement de limites de vitesse fondées sur le retour sur expérience, ainsi que pour le contrôle policier de ces limites.
Source: Ravishankar Rajaraman, Manager - Safety Group, JPRI.
Mesurer le port de la ceinture de sécurité et du casque
Le FMSR a développé deux manuels distincts, l’un consacré aux ceintures de sécurité et systèmes de retenue pour enfants (FMSR, 2009), et l’autre aux casques (FMSR, 2006). Ces manuels montrent comment évaluer l’étendue du non-port de la ceinture de sécurité et du casque dans une région projetée, et comment concevoir, mettre en œuvre et évaluer un programme pour aborder ce problème. Ils donnent aussi une liste de sources possibles sur les manières de mesurer le port de la ceinture de sécurité et du casque, et sur le recueil de données à travers des enquêtes communautaires et des études d’observation.
Le FMSR a aussi développé un autre manuel de sécurité routière, similaire aux deux précédents, sur l’alcool au volant (FMSR, 2007), qui indique comment évaluer la situation et choisir des actions prioritaires, et comment concevoir, mettre en œuvre et évaluer un programme de lutte contre l’alcool au volant.
Ce guide suggère de collecter les données auprès des autorités pertinentes, telles que la police, les autorités routières et les secteurs de la santé, pour évaluer le problème. Les données sur le respect des règles de circulation existantes peuvent être obtenues à partir d’une combinaison de données sur les accidents (c’est-à-dire ceux impliquant des conducteurs et usagers avec un taux d’alcoolémie supérieur à la limite légale), du nombre d’infractions relatives à l’alcool détectées par la police, du pourcentage de conducteurs arrêtés avec un taux d’alcoolémie dépassant la limite légale, et au moyen d’enquêtes de comportement/résultats auprès des conducteurs (FMSR, 2007).
Il existe une variété d’autres résultats intermédiaires qui pourraient être mesurés, selon le type d’intervention mis en place.
En ce qui concerne les données sur les accidents, il est important que les données d’enquêtes soient enregistrées de manière à pouvoir être analysées facilement, et que le système permette de les croiser et de les comparer avec celles d’autres sources. Ceci est particulièrement vrai pour les enquêtes couvrant de vastes zones géographiques (par exemple, volume de circulation, données démographiques ou sur les l’infrastructure routière), et de tels systèmes peuvent déjà exister pour ces types de données. Une méthode commune est le croisement géographique des données par site, au moyen d’un système SIG (Système d’Information géographique). Typiquement, les systèmes SIG peuvent stocker une information croisée géographiquement pour une future analyse, et accepter plusieurs « couches » de différents types de données, ce qui permet une évaluation du risque plus poussée (voir Paragraphe 5.6).
Pour collecter, gérer et utiliser des données sur la sécurité routière, il est important de garder à l’esprit que la qualité des données peut se trouver compromise à n’importe quel stade du processus, du fait :
La faible qualité et la sous-déclaration des données sur les accidents peuvent avoir des conséquences (Austroads, 2005; OCDE, 2007), telles que :
Le présent chapitre se consacre aux facteurs qui affectent la qualité des données, aux méthodes d’étude des incohérences entre les données, et aux manières d’améliorer leur qualité. Bien que ce chapitre ne traite que des données sur les accidents, les problèmes de qualité se posent également pour les autres données qui doivent être recueillies et interprétées avec précautions.
Il arrive parfois que les données soient enregistrées de manière incorrecte par la police ou le personnel de saisie. Il est important de noter que, dans la plupart des cas, la personne qui remplit le formulaire sur le lieu de l’accident n’est pas la même qui saisira les données dans le système (OCDE, 2007). Les données incorrectes, incomplètes ou manquantes sont très rarement un fait intentionnel, et presque toujours le résultat d’une erreur humaine. Du fait de ses priorités et de sa charge de travail, la police ne peut pas toujours se rendre sur les lieux d’un accident ou avoir le temps de complètement remplir le formulaire d’accident (ce qui peut être pire dans le cas d’un formulaire de collecte inutilement long). Des définitions peu claires des champs (voir paragraphe suivant) peuvent aussi avoir pour conséquence une saisie incorrecte ou incomplète des données. Des situations similaires peuvent se rencontrer avec des données autres que celles concernant les accidents. Par exemple, des données sur l’infrastructure routière peuvent être encodées de manière incorrecte, ou des erreurs de saisie peuvent se produire lors d’une analyse des données sur la vitesse.

© ARRB Group
La définition de chaque champ (type d’accident, gravité des blessures, lieu de l’accident, etc.) peut différer selon les sources de données (par exemple, dossiers de la police sur les accidents, dossiers des hôpitaux, déclarations de sinistres auprès des assurances), les pays et les régions. Ceci peut amener des complications dans l’identification des accidents considérés, dans la comparaison des bases de données, et dans l’évaluation de la qualité des données. Les définitions confuses les plus communes sont examinées ci-après.
Les catégories les plus communes de gravité des blessures sont les blessures mortelles, les blessures sérieuses/graves, et les blessures légères/sans gravité. Cependant, les méthodes utilisées par la police et les hôpitaux pour déterminer quelles blessures appartiennent à quelle catégorie de gravité peuvent être source de problèmes.
Une question qui revient toujours dans la comparaison des bases de données de différents pays est le cadre temporel qui s’applique aux accidents et blessures mortels. La règle des 30 jours définit un accident mortel comme un accident dans lequel la victime meurt sur-le-champ ou des blessures occasionnées par l’accident (à l’exclusion des suicides) dans les 30 jours suivants. La règle des 30 jours est la classification la plus commune dans le monde, en particulier dans les pays à revenu élevé et intermédiaire (OMS, 2010). D’autres pays, en particulier les pays à revenu faible, utilisent les définitions « sur les lieux » ou « dans les 24 heures » pour classifier les blessures, ce qui peut créer des incohérences entre les bases de données. Des facteurs d’ajustement ont été développés pour prendre ces différences en considération (OMS, 2010), mais ceci suppose cependant que des proportions similaires d’usagers vulnérables existent dans chaque système, ce qui n’est pas forcément le cas (OMS, 2010).
De plus, la règle des 30 jours implique un certain degré de coordination entre les officiers de police présents sur les lieux de l’accident et le personnel de l’hôpital, afin de mettre le dossier de l’accident à jour après la période de 30 jours. Toutefois, ceci n’est pas toujours le cas, du fait des différentes priorités et de la charge de travail des parties intéressées (OMS, 2010). La même question se pose en ce qui concerne la classification des blessures non mortelles, Une blessure grave est souvent classifiée comme « admission à l’hôpital », mais la police utilise souvent la classification de « toute personne quittant les lieux de l’accident dans une ambulance » (Austroads, 2005).
De même, il existe des différences entre ce que les hôpitaux considèrent comme une « blessure grave » (voir IRTAD 2011 pour un examen détaillé de cette question). Un nombre croissant de patients est envoyé dans des cliniques spécialisées (par exemple, cliniques de fractures) au lieu d’être hospitalisé. De ce fait, il est difficile de dire, dans certaines bases de données, si la tendance qui montre moins d’hospitalisations est le résultat d’un changement de la gravité des blessures ou d’un changement dans le système de gestion des services de santé (Ward, Lyons & Thoreau, 2006). L’IRTAD (2011) recommande que le statut de « blessure grave » soit attribué par le personnel qualifié des hôpitaux et non par la police sur les lieux de l’accident. Dans la réalité cependant, de telles vérifications sur le statut de la gravité des blessures ne sont pas souvent effectuées, et il revient à la police de déterminer sur les lieux de l’accident la gravité des blessures.
Dans certains pays, il est obligatoire de déclarer les accidents « sans blessures » ou avec seulement des « dommages matériels », et dans d’autres, non. Parfois le niveau de dommages doit dépasser un certain seuil monétaire pour être déclaré. Ce type d’informations supplémentaires peut être d’utilité, en particulier pour identifier le lieu de l’accident et de sa cause probable, et n’implique pas un coût plus élevé en termes de collecte et de saisie des données.
La définition des accidents de la circulation ou accidents de la route peut incorporer ou exclure les accidents impliquant des véhicules non motorisés. Elle peut aussi exclure les accidents survenus sur des routes privées ou des sites hors de la route tels que des parcs ou des stationnements. Certains pays collectent les informations sans égard au site (OMS, 2010).
Un autre problème courant est que les dossiers des patients externes des hôpitaux ne se concentrent souvent que sur la nature de la blessure (par exemple, fémur cassé), et négligent parfois de mentionner la cause de la blessure. Ceci peut rendre pratiquement impossible l’identification des cas liés à des accidents de la route, et réduit aussi l’information disponible permettant d’identifier et de traiter les lieux des accidents (OMS, 2010).
Plusieurs méthodes différentes sont utilisées pour déterminer les lieux d’un accident (chapitre 5.3), et chacune de ces méthodes peut être sujette à erreur. Il peut en résulter un enregistrement inexact ou imprécis du lieu de l’accident par la police, et rendre difficile l’évaluation de l’importance de sites particuliers d’accidents.

La sous-déclaration peut survenir à n’importe quel stade du processus de collecte et de saisie des données. L’OMS (2010) examine en détail les facteurs contribuant à la sous-déclaration dans les données de la police et des services de la santé. La sous-déclaration varie souvent selon la gravité des blessures, le mode de transport, le type d’usager de la route, l’âge des victimes et le lieu de l’accident. Les principales conclusions (Austroads, 2005; Ward, Lyons, Thoreau, 2006) indiquent que :
Cette question de la sous-déclaration peut être un problème significatif dans tous les pays, en particulier dans les PRFIs (Encadrés 5.10 et 5.11).
Le Rapport mondial de situation (OMS, 2013) utilise des estimations fondées sur un modèle de régression, pour les pays qui ne déclarent pas à l’OMS les décès enregistrés sous un format spécifique. Dans de nombreux cas, les estimations de l’OMS diffèrent considérablement des taux officiels déclarés de décès sur la route. Il a été estimé que certains pays ne déclarent que 15 à 20% des décès par accident de la route, et dans un cas, seulement 2,5%. De toute évidence, il y a beaucoup à faire pour améliorer les taux de déclaration.
L’étude de cas sur le système RCVIS au Cambodge (Paragraphe 5.3.2) met en lumière une approche possible, qui implique le recueil de données auprès de deux sources et qui a réduit de manière significative la sous-déclaration dans le pays. Une approche similaire a été adoptée en Indonésie, où des démarches ont été entreprises en 2009 pour améliorer le recueil de données, y compris le recoupement des données de la police avec celles des compagnies d’assurance et des hôpitaux. Le graphique ci-dessous montre que la déclaration des données a augmenté de manière substantielle à la suite de cette initiative.
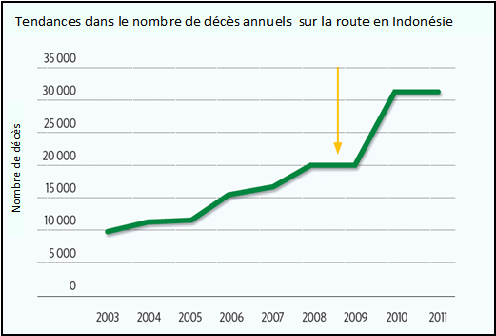
L’OMS (2013) a signalé que cette action a eu comme résultat inattendu une augmentation substantielle du nombre des accidents de la circulation en 2010. Cette augmentation apparente n’est pas le résultat d’une augmentation réelle du nombre des décès par accident de la route, mais d’une amélioration du taux de déclaration des décès survenus. Plusieurs pays ont connu la même expérience d’une augmentation apparente du nombre des décès, alors qu’il s’agissait en fait d’une amélioration de l’exactitude des données. Cette amélioration des données permet une meilleure identification et une meilleure gestion des problèmes de sécurité routière. Cependant, l’illusion, que le nombre des accidents a augmenté, est aussi une question qui doit être gérée.
Source: OMS, (2013).
Au Mexique, l’Institut pour les Statistiques et la Géographie (INEC) a généré des statistiques officielles fondées sur le recueil de l’information sur les accidents de la route auprès de la police locale et des tribunaux, ainsi que de la police fédérale dans le cas des accidents sur les routes fédérales. Les décès sur les lieux de l’accident sont enregistrés à partir de ces sources, ce qui a donné en 2012 le chiffre de 10 008 morts. Par ailleurs, le Ministère de la Santé gère aussi une base de données à partir des certificats de décès déclarant un accident de circulation comme leur cause. A partir de cette seconde source, tous les décès de ce type sont enregistrés, et ceci a donné en 2012 le chiffre de 17 653. La différence entre les chiffres de ces deux sources provient des décès qui ne surviennent pas sur les lieux de l’accident, mais quelque temps après celui-ci. De plus, le chiffre de 17 653 en 2012 sous-estime le nombre total des décès dus à des accidents de la route, parce que dans le cas des accidents postérieurs à l’accident, le certificat de décès n’indique pas l’accident comme sa cause, mais une cause différente (par exemple, arrêt cardio-pulmonaire, mort cérébrale, infection, défaillance d’un organe).
Typiquement, les niveaux élevés de gravité des blessures ont les meilleurs taux de déclaration. De nombreux pays (en particulier les PREs) enregistrent tous les accidents mortels et ont un niveau raisonnable d’enregistrement des blessures les plus graves (par exemple, hospitalisations). Il est tout aussi courant que les blessures sans gravité soient moins déclarées. Une manière rapide de déterminer l’échelle probable des taux de sous-déclaration des accidents non mortels est de comparer les ratios des accidents mortels avec ceux d’autres types d’accident entre pays et régions. Bien qu’un certain nombre de facteurs doivent être pris en considération (par exemple, type de route, parc des véhicules, vitesses moyennes, etc.), l’écart entre ces ratios peut indiquer des différences dans les taux de déclaration.
Les ensembles de données peuvent être évalués pour déterminer les niveaux de sous-déclaration et de qualité des données par comparaison avec d’autres bases de données. Une comparaison commune est celle des données de la police sur les accidents avec celles des hôpitaux sur les patients internes. Une autre source est celle des données de déclarations de sinistres auprès des compagnies d’assurance. Bien que ces évaluations soient très utiles, elles ne permettent pas de déterminer le nombre total réel d’accidents, parce qu’il n’existe aucun moyen de connaître le croisement exact de deux bases de données (OCDE, 2007). Certains accidents seront enregistrés dans la base de données sur les accidents de la police, mais comme les victimes ne sont pas toujours envoyées ou admises à l’hôpital (dans les accidents ne causant que des dommages matériels ou des blessures sans gravité), ils n’apparaîtront pas dans les bases de données des hôpitaux. A l’inverse, il y aura évidemment dans les bases de données des hôpitaux des enregistrements de blessures qui ne sont pas liées à des accidents.
Comparer les données de la police et celles des hôpitaux permet d’apprécier l’exactitude des cas d’accidents (en s’assurant que l’information saisie dans les deux bases de données soit la même) et aussi de poser les bases permettant d’estimer la proportion de cas non déclarés aussi bien dans les dossiers de la police que dans ceux des hôpitaux, ainsi qu’illustré dans le diagramme ci-dessous (OCDE, 2007).

Un problème commun avec cette technique est que certains pays ne permettent pas la diffusion du nom de la victime, et parfois même de codes d’identification personnelle. Les cas ne peuvent être associés que par d’autres caractéristiques (par exemple, heure, date et lieu de l’accident) (Austroads, 2005). Les données ne peuvent être conservées de manière fiable que si leur qualité est vérifiée régulièrement. L’OMS (2010) et l’IRTAD (2011) donnent plus de détail sur les méthodes d’évaluation de la qualité des données et sur les taux de sous-déclaration.
Il n’est typiquement pas possible de recueillir avec succès les données pour chaque accident survenu sur un réseau, mais il n’est pas nécessaire d’enregistrer tous les accidents pour pouvoir tirer des conclusions et identifier les priorités pour améliorer la sécurité routière (Austroads, 2005). Cependant, plus les bases de données sont complètes, plus leur fiabilité est grande.
Les principales étapes pour améliorer la qualité des données comprennent :
Le paragraphe 3.4.1 de l’OMS (2010) examine en détail de quelle manière les étapes énumérées ci-dessus peuvent être mises en œuvre. Il présente des solutions efficaces telles que le bénéfice tiré des systèmes de saisie de données comportant des fonctions intégrées de vérification pour minimiser les erreurs, et celui de maintenir la police informée des résultats afin que les agents se rendent compte de la valeur et de l’importance de cette tâche et de leur rôle dans son accomplissement. Il est également important de reconnaître qu’un équilibre doit être trouvé dans le nombre de détails que la police doit enregistrer sur les lieux d’un accident. Trop de questions auront pour résultat des rapports d’accidents incomplets ou manquants, et trop peu de questions limiteront les détails essentiels nécessaires pour les futures analyses.
Les données sur les accidents peuvent être extrêmement utiles pour un ensemble d’agences et de personnes :
Le chapitre suivant s’intéresse à la disponibilité des données sur les accidents, aux différents usagers, et aux efforts coopératifs internationaux actuels visant à améliorer ces données.
Selon l’OMS, des méthodes appropriées de partage des données avec chaque agence qui le demande devraient être mises en place, au moyen de rapports statistiques, de bulletins d’information, de sites Internet et d’ateliers de travail (OMS, 2010). Un excellent moyen de diffuser les données sur les accidents, si le financement est disponible, est une base de données publique et interrogeable en ligne, qui peut offrir des rapports personnalisés selon le lieu de l’accident, le type de blessures ou autres caractéristiques (OMS, 2010). L’Encadré 5.12 donne un exemple d’un tel système.
CrashMap (www.crashmap.co.uk ) est un outil en ligne, ouvert au public permettant des recherches sur les accidents (par gravité) pour savoir où et quand ils sont survenus. Les utilisateurs peuvent décider d’inclure tous les types d’accidents graves dans leur recherche, ou la limiter aux accidents impliquant des motocyclistes, des cyclistes, des piétons, ou des enfants. Les résultats de la recherche montrent une carte des lieux des accidents, marquée de repères en couleur indiquant le degré de gravité. Alternativement, les repères peuvent être d’une seule couleur mais montrer un chiffre supérieur à 1, indiquant que de multiples rapports d’accident existent pour un emplacement particulier. Chaque repère fournit une vue générale des circonstances de l’accident, y compris sa date, sa gravité, et le nombre de véhicules et de victimes impliqués. Souscrire au site permet des recherches encore plus détaillées sur les accidents pour un coût minime, lequel finance la tenue à jour du service.
Les médias sont une autre méthode efficace de diffusion des données, et peuvent agir en influençant les opinions publiques et politiques.
Il est important de garder à l’esprit qu’indépendamment de la méthode de diffusion, les responsables des données sur les accidents ont aussi la responsabilité de protéger la vie privée des personnes impliquées. L’OMS (2010) a décrit les démarches nécessaires à cette fin.

Les données peuvent être utilisées pour accroître la prise de conscience de certains problèmes particuliers au regard de la sécurité routière, et servir pour attirer l’appui à certains programmes, politiques ou l’affectation de ressources (OMS, 2010). Les activités usuelles de plaidoyer ou défense de la cause sont les ateliers de travail, les reportages et les campagnes d’information. Le plaidoyer ou la promotion de la cause sont importants pour la sécurité routière, pour dégager des sources de financement et le soutien du public. Il convient de noter que tout matériel pour la défense ou promotion de la cause doit prendre en compte l’audience sélectionnée et le contexte de la recommandation ou cause défendue pour avoir l’effet désiré. L’OMS (2010) donne des conseils à l’intention des décideurs politiques pour le développement de messages de promotion. L'Encadré 5.13 montre l’utilisation des données de sécurité routière aux fins de plaidoyer et promotion de la cause au Cambodge.
Le problème : en dépit de l’existence d’une base de données bien développée pour l’analyse des accidents de la route, l’information capitale n’était pas transmise aux parties prenantes concernées.
La solution : reconnaissant que des rapports trop longs ne sont probablement pas lus par les gestionnaires et politiciens de haut niveau, le Comité national sur la Sécurité routière du Cambodge a passé en revue les rapports du système de données sur les accidents. Un rapport résumé est maintenant préparé en plus des rapports détaillés. Il contient les titres principaux de l’analyse sur les conséquences des accidents, ainsi que des graphiques, tableaux et cartes claires et faciles à interpréter, pouvant être rapidement lus et compris. Cette information résumée est particulièrement utile aux fins de défense et de promotion de la cause, et pour informer les hautes autorités sur les problèmes critiques. Les rapports détaillés restent à la disposition des intéressés (par exemple, les personnels techniques).
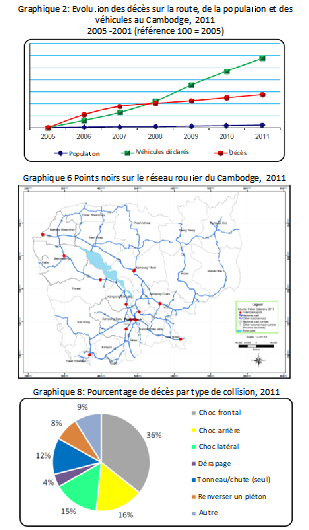

Les résultats : l’information est présentée de différentes manières en fonction des besoins de l’utilisateur final, ce qui la rend désormais plus accessible aux principales parties prenantes.
Identifier les problèmes de sécurité routière
Les utilisateurs les plus courants des bases de données fondées sur l’information de la police sont les ingénieurs routiers, pour leurs travaux sur la sécurité. Les données sur les accidents sont utilisées pour identifier les sites à haut risque d’accident et si possible les facteurs de risque propres à ces sites. Ceci est expliqué plus en détail au Chapitre 10.
Pour identifier des sites à haut risque d’accidents, des groupes ciblés ou des facteurs particuliers de risque, les décideurs utilisent les données sur les accidents pour évaluer le problème, en termes des comptages, de la gravité, des tendances et des coûts des blessures (OMS, 2010). Il est donc important que ces professionnels aient accès aux caractéristiques des accidents telles que la tranche d’âge, le type d’accident et la catégorie d’usagers de la route, afin de pouvoir prendre des décisions éclairées quant à la priorité à donner aux problèmes à haut risque et aux solutions pouvant être efficacement mises en œuvre.
La police peut aussi utiliser ses données pour cibler ses opérations de contrôle du respect des règles de circulation sur un problème ou un site particulier. Il est important que la police reçoive un retour d’information régulier, afin qu’elle puisse constater l’impact de ses efforts de recueil de données et d’application des règles de circulation (OMS, 2010).
Suivre et évaluer les résultats des initiatives
Les données sur les accidents sont essentielles pour évaluer les nouveaux traitements et les politiques. Les évaluations fournissent une base de connaissances sur l’efficacité d’un traitement donné, et permettent d’assurer que les programmes actuels produisent les résultats attendus et désirés.
Les nouvelles analyses peuvent renforcer l’efficacité connue d’une initiative, au moyen par exemple du développement de facteurs modificateurs des accidents (FMAs). Le Chapitre 12 offre plus d’information sur le suivi et l’évaluation des contremesures de sécurité routière, y compris l’efficacité des traitements et le développement de FMAs.
La coopération internationale est essentielle pour la coordination et la comparaison. L’évaluation internationale peut aider à identifier et suivre les problèmes de sécurité routière, et à estimer l’efficacité de toute méthode mise en œuvre à grande échelle. La comparaison des résultats de la sécurité routière (avec d’autres pays, régions, villes, etc. similaires) peut conduire à l’identification de problèmes devant être abordés. Il est important de noter que ceci n’est pas réalisable sans une cohérence entre les définitions des champs. La coordination aide aussi les pays et les gouvernements à améliorer leurs systèmes de collecte et la qualité des données de sécurité routière (Encadré 5.14).
.")
Figure 5.8 - Source: OECD/ITF, (2014).
En 1988, l’Organisation pour la Coopération et le Développement économique (OCDE) a établi la base internationale de données sur la circulation et les accidents de la route (IRTAD), qui contient des données pour plus de 30 pays, qui sont continuellement mises à jour et analysées pour en extraire des tendances. Cette base de données contient des informations sur la gravité des accidents, les catégories d’usagers de la route et leur âge, et aussi des détails pertinents tels que la population, la composition du parc des véhicules, la longueur du réseau routier, et les taux de port de la ceinture de sécurité. Ceci a permis des comparaisons très utiles entre les taux de décès des pays (par exemple, taux de décès routiers par 100 000 habitants). Le Groupe de l’IRTAD est un groupe de travail composé de statisticiens et d’experts en sécurité routière du monde entier. Son objectif principal est de contribuer à la coopération internationale en matière de collecte et d’analyse des données de sécurité routière. Ceci se fait à travers : 1) l’échange d’information sur les données recueillies, les systèmes de déclaration et les tendances dans les politiques, la recherche et les publications sur des problèmes critiques et émergeants en matière de sécurité routière, et 2) l’apport de conseils sur des questions spécifiques de sécurité routière aux pays membres. Le Groupe de l’IRTAD est également chargé du développement du réseau IRTAD et de la couverture de la base de données, de programmes de jumelage pour aider les PRFIs à améliorer leurs systèmes de collecte et de déclaration des données, de la Conférence de l’IRTAD, et de la publication du rapport annuel. Il produit aussi des définitions normalisées et des méthodologies de comparaison (par exemple, définition de la gravité des accidents et des blessures).
Dans le cadre de sa stratégie de sensibilisation dans les PRFI, l’IRTAD a lancé un programme de jumelage et travaille avec plusieurs organisations pour aider les PRFIs à améliorer leurs méthodes pour le recueil de données, l’établissement et la gestion de bases de données sur les accidents de la route. Il existe plusieurs de ces accords, comme les programmes de jumelage entre le Cambodge et les Pays-Bas, la Jamaïque et le Royaume-Uni, l’Argentine et l’Espagne ; d’autres partenariats sont en cours de développement. L’étude de cas de l’Encadré 5.15 renseigne sur l’accord de jumelage entre l’Argentine et l’Espagne, l’Encadré 5.16 offre plus de détails sur un observatoire régional en Amérique Latine.
Le problème : le manque d’information fiable et exhaustive sur les accidents au niveau national en Argentine.
La solution : en Avril 2010, la Banque mondiale a fourni le financement pour l’établissement d’un jumelage entre l’Argentine et l’Espagne, en lien avec l’IRTAD. L’Espagne a assisté l’Argentine dans l’amélioration de son système de recueil et d’analyse des données, en vue d’aider l’Agence nationale pour la Sécurité routière (ANSV, Agencia Nacional para la Seguridad Vial), l’agence chef de file en Argentine, à devenir un membre de l’IRTAD.
Le programme de jumelage impliquait des voyages d’étude en Espagne et l’apport de conseils sur la gestion des interventions en sécurité routière. L’aspect principal du programme était l’assistance au développement d’un système national, exhaustif et cohérent, de gestion des données sur les accidents. Le programme comprenait aussi la formation de praticiens dans toutes les juridictions, aux niveaux municipal, provincial et national, afin d’assurer une qualité et une analyse normalisées des données dans la préparation des diagnostics et des rapports.
Les résultats : grâce au développement d’une base de données nationale sur les accidents, les données de toutes les juridictions ont été recueillies au moyen d’un formulaire normalisé, afin de permettre l’inclusion de la base de données de l’ANSV dans le Groupe IRTAD. Le programme de jumelage a aussi créé l’accès au conseil d’experts, à l’information technique et à des méthodologies de recherche. Le succès du programme de jumelage a permis l’inclusion de l’Argentine dans la base de données IRTAD, ainsi qu’une coopération plus large en Amérique Latine, ce qui, à son tour, a conduit à la création de l’Observatoire latino-américain de la sécurité routière (OISEVI).
Le problème : le manque de capacité régionale pour collecter et analyser les données de sécurité routière.
La solution : le jumelage réussi entre l’Espagne et l’Argentine a eu pour effet l’établissement d’une coopération plus large entre des pays de l’Amérique latine et de la région caribéenne, baptisée l’Observatoire latino-américain de la sécurité routière (OISEVI).
Cet Observatoire a été créé en 2011 ; 18 pays s’y sont joints dans le but de partager les connaissances et les meilleures pratiques en matière de planification et d’établissement de politiques. L’objectif principal de l’OISEVI est de partager l’information sur la sécurité routière, en particulier les meilleures pratiques en formulation de politiques, planification, stratégies et gestion des données en matière de sécurité routière. L’Observatoire vise aussi à améliorer l’expertise et le partage des connaissances entre les praticiens de la sécurité routière, et à améliorer les résultats de celle-ci en Amérique latine.
L’OISEVI est soutenu par une base régionale de données sur la sécurité routière (hébergée par l’OCDE/ITF) fondée sur le modèle IRTAD, et destinée à aider les pays de l’Amérique latine et des Caraïbes. Cette base de données utilise les mêmes définitions et pratiques de déclaration normalisées que le système central IRTAD, et a pour raison d’être des améliorations progressives dans la qualité des données, au fil des ans. Au vu du succès de ce modèle, l’OCDE/ITF explore les opportunités de reproduire cette approche dans d’autres régions du monde.
La base de données IRTAD LAC est une sorte de base de données « miroir », qui a la même structure que la base principale de données IRTAD, et est fondée sur la même enquête. La principale différence est qu’elle est un outil d’apprentissage, dans lequel les pays peuvent inclure leurs données nationales, même si elles sont incomplètes ou fondées sur des estimations. IRTAD LAC leur permet de se familiariser avec les exigences de l’IRTAD, de s’adapter aux méthodes de recueil de l’IRTAD (si nécessaire), et de se comparer avec les pays voisins. Une fois que les données sont consolidées et plus complètes, elles sont examinées par le Groupe de l’IRTAD en vue de leur inclusion dans sa base de données principale.

Les résultats : l’Observatoire a produit trois rapports annuels consolidant les données régionales de sécurité routière. Des conférences techniques ont aussi été tenues sur des sujets pertinents à leur région (par exemple, un atelier de travail sur la sécurité des motocyclettes). Les données de la ligne de référence ont été recueillies pour analyser les changements de comportement (sur la route) dans des pays pilotes. Les données ont été recueillies au moyen d’enquêtes d’observation sur les facteurs de risque d’accidents, tels que le non-port de la ceinture de sécurité, la distraction du conducteur, l’usage ou non de systèmes de retenue pour enfants, et la conduite en état d’ivresse.
L’Encadré 5.17 est consacré à la déclaration de l’IRTAD/OISEVI de Buenos Aires, Argentine, pour de meilleures données en vue de meilleurs résultats de sécurité routière.
En novembre 2013, 40 pays se sont joints à la Conférence IRTAD/OISEVI à Buenos Aires. La réunion a conduit à l’approbation de 12 recommandations en vue de meilleures données de sécurité routière pour de meilleurs résultats dans ce domaine :
des données factuelles (incluant le nombre de victimes tuées ou blessées par catégories d’usagers de la route, la date et l’heure de l’accident, etc.),
des données au niveau des produits (y compris des indicateurs de performance) et
des données contextuelles (y compris les données sur l’exposition au risque, telles que population, nombre de véhicules, distances parcourues).
Le site Internet suivant offre plus de détail : http://www.internationaltransportforum.org/jtrc/safety/Buenos-Aires-Declaration.html
En Europe, la base centralisée de données CARE (Community Road Accident Database – Base commune de Données sur les Accidents) est hébergée par la Commission européenne et contient des informations sur les accidents mortels et avec blessés. Les détails sur les accidents individuels sont conservés (c’est-à-dire que cette information n’est pas combinée), ce qui permet une analyse plus poussée. Un protocole de collecte des données a été développé, avec des variables communes spécifiées. La raison d’être de cette base de données est de rassembler les éléments permettant de :
Le site Internet de la Commission européenne offre plus d’information sur CARE :
Intégrer les données sur la sécurité routière offre de grands avantages, parmi lesquels :
Les principaux croisements de données incluent la combinaison de données sur les accidents avec des données sur la circulation, l’infrastructure routière, l’immatriculation des véhicules, l’inspection des véhicules et les statistiques démographiques.
Le processus de croisement se fait en plusieurs étapes, et peut être temporaire (par exemple, pour un projet spécifique ou des besoins de la police), ou permanent (par exemple, pour l’analyse et le suivi en continu). Les données doivent être recueillies dans un format facilitant le croisement, ce qui requiert habituellement la disponibilité d’éléments communs de données, Pour les éléments de la route (y compris les accidents), les données les plus utiles sont les coordonnées spatiales. Les données non spatiales requièrent un identifiant unique afin de pouvoir être croisées. Un système exhaustif d’information sur la sécurité peut avoir un grand nombre de fichiers composants.
Après avoir été croisées, les données peuvent être analysées par fusion des fichiers de données. Pour les données spatiales, un logiciel SIG peut être de grande utilité, en particulier pour cartographier les informations des différentes sources.
Après l’investissement initial, il peut être relativement peu coûteux de rassembler différentes sources d’information pour satisfaire une variété de besoins, et plus particulièrement si un identifiant unique a été attribué à chaque ensemble de données. Dans d’autres circonstances, et surtout si les données n’ont pas été saisies dans des formats compatibles, la tâche peut être assez considérable et impliquer un investissement substantiel.
L’une des fonctions de croisement les plus communes est celle du calcul des taux d’accidents, qui permet de comparer ou d’identifier les emplacements à haut risque. Par exemple, les données sur les accidents peuvent être combinées avec des chiffres de démographie, de volumes de circulation, ou d’immatriculation de véhicules pour permettre d’utiles comparaisons du risque. Dans l’idéal, celles-ci sont présentées comme un taux d’accident mortel ou causant des blessures graves. Chacune de ces mesures est utile à différentes fins, telles que :
Les données sur les accidents peuvent aussi être combinées avec des données sur l’inventaire des routes. À un niveau simple, ceci peut fournir des informations sur les caractéristiques actuelles d’une route, et sur de possibles améliorations de la sécurité de l’infrastructure. Par exemple, les données sur les accidents en sortie de route peuvent être présentées en parallèle avec les données sur l’emplacement des barrières latérales (sur les accotements) sur une carte, permettant une rapide analyse visuelle des endroits qui pourraient bénéficier de l’installation de nouvelles barrières.
L’Encadré 5.18 décrit le Système d’Information sur la Sécurité des routes aux États-Unis.
Le Système d’Information sur la Sécurité des Autoroutes (HSIS, Highway Safety Information System) des États-Unis est géré sous contrat par l’Administration fédérale des routes (FHWA). Le système HSIS contient des informations sur :
L’information sur les caractéristiques concernant les courbes, pentes et carrefours est également disponible pour certains États. La combinaison des différentes sources de données permet une analyse poussée de problèmes spécifiques de sécurité routière.
Un grand nombre d’études ont été effectuées à partir de cette riche source d’information, avec la production de plusieurs rapports, résumés et outils de recherche. Des exemples récents incluent :
Le site Internet de HSIS offre plus d’information : www.hsisinfo.org
Les récentes initiatives d’intégration des données impliquent la combinaison de données sur les accidents avec des données sur l’évaluation des risques routiers. Ceci fournit un outil très puissant pour identifier les sites à haut risque et les solutions possibles. Le Chapitre 10.5 et le Chapitre 11 explorent plus en détail la combinaison de ces données.

Par une évaluation des besoins de données :
Austroads (2005), Australasian road safety handbook volume 3, Why we continue to under-count the road toll, Austroads, Sydney, Australia.
DETR (2001), A road safety good practice guide for highway authorities, DETR, London, United Kingdom.
Global Road Safety Facility GRSF (2009), Implementing the Recommendations of the World Report on Road Traffic Injury Prevention. Country guidelines for the Conduct of Road Safety Management Capacity Reviews and the Specification of Lead Agency Reforms, Investment Strategies and Safe System Projects, Global Road Safety Facility World Bank, Washington DC.
Global Road Safety Facility GRSF (2013), Road Safety Management Capacity Reviews and Safe System Projects, Global Road Safety Facility, World Bank, Washington, DC.
GRSP (2006), Helmets: a road safety manual for decision-makers and practitioners, WHO, Geneva, Switzerland.
GRSP (2007), Drinking and driving: a Road Safety Manual for Decision-makers and Practitioners, Global Road Safety Partnership, Geneva, Switzerland.
GRSP (2008), Speed management: a Road Safety Manual for Decision-Makers and Practitioners, GRSP, Geneva, Switzerland.
GRSP (2009), Seat-belts and child restraints: a road safety manual for decision-makers and practitioners, FIA Foundation for the Automobile and Society, London, United Kingdom.
IRTAD (2011), Reporting on serious road traffic casualties: combining and using different data sources to improve understanding of non-fatal road traffic crashes, Organisation for Economic Co-operation and Development (OECD), Paris, France.
Mansfield, H, Bunting, A, Martens, M & van der Horst, R (2008), Analysis of the On-the-Spot (OTS) road accident database. Road Safety Research Report 80, Department for Transport, London, United Kingdom.
OECD (2007), IRTAD special report: Underreporting of road traffic casualties, OECD, Paris. France.
OECD/ITF (2014) IRTAD Road Safety Annual Report 2014, Organisation for Economic Co-operation and Development (OECD), Paris, France.
Ruengsorn, D, Chadbunchachai, W, & Tanaboriboon, Y, (2001), Development of a GIS based Accident Database through trauma management system: the developing countries experiences, a case study of Khon Kaen, Thailand, Journal of the Eastern Asia Society for Transportation Studies, 4, 5, 293-308.
Thomas, P, Muhlrad, N, Hill, J, Yannis, G, Dupont, E, Martensen, H, Hermitte, T, Bos, N (2013) Final Project Report, Deliverable 0.1 of the EC FP7 project DaCoTA.
Turner, B & Hore-Lacy, W, (2010), Road safety engineering risk assessment part 3: review of best practice in road crash database and analysis system design, Austroads, Sydney, Australia.
United Nations Road Safety Collaboration (UNRSC), (2011), Global Plan for the Decade of Action for Road Safety 2011 – 2020, World Health Organization, Geneva.
Ward, H, Lyons, R & Thoreau, R (2006), Under-reporting of road casualties: phase I. Road Safety Research Report 69, Department for Transport, London, United Kingdom.
WHO, (2010), Data systems: a road safety manual for decision-makers and practitioners, World Health Organization, Geneva, Switzerland.
WHO, (2013), Global Status Report on Road Safety 2013, World Health Organization, Geneva, Switzerland.