





ANNEXE 12.1 – TESTS STATISTIQUES
TEST DE STUDENT – COMPARAISON DE MOYENNES D’ÉCHANTILLONS
Pour déterminer si la vitesse moyenne d’un échantillon de mesures de vitesses est significativement différente de celle d’un autre échantillon (par exemple, dans le cadre d’une étude avant/après), il convient d’effectuer un test de Student bilatéral, en posant comme hypothèse que les variances des deux échantillons proviennent d’une même population. L’hypothèse nulle stipule donc qu’il n’y a pas de différence entre les moyennes (c’est-à-dire que la vitesse des conducteurs n’a pas été influencée par l’intervention). Il faut au préalable calculer l’écart type de la différence entre ces moyennes. On peut ensuite calculer les équations suivantes :

Il faut alors comparer la valeur calculée de t à celle donnée par la loi de Student (Tableau 12.A1), pour (na + nb – 2) degrés de liberté (𝜈). Si la valeur calculée de t dépasse celle correspondant au seuil de 5 % (colonne t = 0,05), on peut alors conclure, avec un niveau de confiance de 95 %, que la vitesse moyenne a changé.
Exemple
Supposons que, dans le cadre d’une étude ponctuelle de la vitesse, les résultats suivants aient été obtenus :

Selon l’équation [EQ. 12.1] :
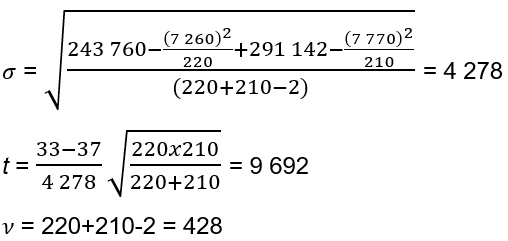
Comme la valeur calculée de t (9,69) est largement supérieure à 1,96 (grand nombre de degrés de liberté), on peut conclure que la différence de vitesses moyennes (réduction de 4 km/h) est significative au niveau de confiance de 5 %.
Ce calcul peut s’effectuer à l’aide du CALCULATEUR : TEST DE DISTRIBUTION t
TABLEAU 12.A1 : TEST DE DISTRIBUTION T

TEST DE KOLMOGOROV-SMIRNOV
Le test « bilatéral » de Kolmogorov-Smirnov permet de déterminer si deux échantillons indépendants proviennent d’une même population (ou de populations ayant une même distribution). Dans certains cas, deux ensembles de données peuvent présenter la même moyenne, mais une dispersion différente, ce qui peut entraîner des problèmes de sécurité. Si les deux échantillons ont effectivement été tirés d’une même population (hypothèse nulle), on peut alors s’attendre à ce que leurs distributions cumulées soient relativement proches, ne montrant qu’un écart aléatoire par rapport à la distribution de population. Si au contraire, les deux distributions cumulées s’éloignent fortement l’une de l’autre à un point quelconque, on peut supposer qu’elles proviennent de populations différentes. Un écart suffisamment important entre ces deux distributions d’échantillons justifie alors le rejet de l’hypothèse nulle.
Soit SNa(x) la fonction échelon cumulative observée pour le premier échantillon de vitesses : SNa(x) = K/Na où K où K représente le nombre de véhicules dont la vitesse est égale ou inférieure à x km/h et Na le nombre total de véhicules de l’échantillon. De même, soit SNb(x) la fonction échelon cumulative du second échantillon. Le test bilatéral de Kolmogorov-Smirnov s’intéresse à l’écart maximal D entre ces deux fonctions.
Pour des échantillons importants (N > 40), les tableaux de Kolmogorov-Smirnov montrent que la valeur de D doit être supérieure ou égale à la valeur suivante pour rejeter l’hypothèse nulle au seuil de 5 % (c’est-à-dire que les échantillons ne sont pas de la même population) :

Le test « unilatéral » permet de déterminer si les deux échantillons proviennent d’une même population ou si les valeurs d’un échantillon sont stochastiquement supérieures à celles de la population dont est issu l’autre échantillon. Ici encore, on calcule l’écart maximal à l’aide de l’équation [EQ. 12.2], et la signification statistique de la valeur observée de D est déterminée par référence à la distribution de khi-deux.
Pour des échantillons de grande taille, la statistique suivante suit une distribution d’échantillonnage qui est approximativement celle d’une distribution de khi-deux à deux degrés de liberté. Voir la table du khi-deux au Tableau 12.A2.
CALCULATEUR : TEST DE KOLMOGOROV-SMIRNOV
TABLEAU 12.A2 : TABLE DU X2

TEST K
Le test k permet de déterminer comment le nombre d’accidents a évolué sur un site donné, en prenant en considération les données d’accidents d’un groupe de sites témoins.
Pour un site donné, ou un groupe de sites ayant reçu un traitement similaire, on a :
où:
a = accidents sur le site « avant » ;
b = accidents sur le site « après » ;
c = accidents sur les sites témoins « avant » ;
d = accidents sur les sites témoins « après ».
Si k < 1, cela indique une diminution des accidents par rapport aux données de contrôle ;
Si k = 1, cela signifie qu’il n’y a eu aucun changement par rapport aux données de contrôle ;
Si k > 1, cela indique une augmentation par rapport aux données de contrôle.
Si l’une des fréquences est égale à zéro, il comvient alors d’ajouter ½ à chaque fréquence. Dans ce cas :

L’équation suivante permet de calculer le pourcentage de changement au site :
Exemple Le Tableau 12.A3 présente les fréquences annuelles d’accidents corporels pour une intersection en T située en milieu semi-urbain, initialement régie par des arrêts sur la voie secondaire, et transformée en carrefour giratoire il y a trois ans. Les données de contrôle utilisées correspondent aux accidents survenus à toutes les intersections avec priorité à l’arrêt du district, sur des périodes strictement identiques de trois ans « avant » et de trois ans « après ». TABLEAU 12.A3 : FRÉQUENCES D’ACCIDENTS CORPORELS AU SITE DE CONTRÔLE
En utilisant la notation et l’équation présentées ci-dessus : Puisque k < 1, il y a eu diminution des accidents sur le site par rapport aux sites de contrôle. Le pourcentage de réduction est, dans cet exemple, de 68 % : (k-1) x 100% = 68% Le calcul peut être effectué à l’aide du calculateur TESTS AVANT-APRES (SITE INDIVIDUEL). |
TEST DU KHI-DEUX
Ce test permet de déterminer si une variation du nombre d’accidents est attribuable au traitement appliqué ou si elle résulte du hasard, et aurait donc pu se produire même en l’absence d’intervention. Le test permet ainsi de déterminer si le changement observé est statistiquement significatif. Il fait appel à un tableau de contingence présentant, pour un ensemble de données, les valeurs observées (O) et les valeurs attendues (E) si la distribution statistique n’avait pas été modifiée. La statistique du khi-deux s’obtient en calculant :

où :
Oij = la valeur observée dans la colonne j, ligne i du tableau ;
Eij = la valeur espérée dans la colonne j, ligne i du tableau ;
m = le nombre de colonnes ;
n = le nombre de lignes.
On consulte alors cette valeur dans une table du khi-deux, qui indique la probabilité que les valeurs « attendues » et « observées » proviennent d’une même population. Il faut aussi connaître le nombre de degrés de liberté, défini comme suit :
Degrés de liberté (ʋ) = (n – 1) (m – 1)
Dans le cas d’une évaluation d’accidents sur un site, où les accidents sont comparés sur des périodes similaires avant et après traitement, en parallèle avec un ensemble de sites de contrôle sur les mêmes périodes, on obtient un tableau de contingence 2 x 2 (2 colonnes et 2 lignes), avec un seul degré de liberté. Pour que le test soit valide, toutes les cellules de ce tableau doivent avoir une valeur minimale de 5.
En utilisant la notation du Tableau 12.A3, on peut calculer la statistique du khi-deux à l’aide de l’équation suivante :

Le résultat obtenu est ensuite comparé aux valeurs de la table du Khi-deux du Tableau 12.A2, pour un degré de liberté (ʋ = 1). Si le résultat du calcul de l’équation est supérieur à la valeur extraite de la table, le changement est considéré comme statistiquement significatif au niveau de confiance correspondant.
Exemple À partir des données de l’exemple précédent et de l’équation [EQ. 12.9] on obtient : 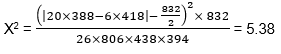 La table du Khi-deux (Tableau 12.A2) indique que, pour un degré de liberté (ʋ =1), la valeur de 5,38 se situe entre 3,84 et 5,41. Cela correspond à un niveau de confiance compris entre 0,05 et 0,02. En d’autres termes, la probabilité que le changement d’accidents observé soit attribuable à une variation aléatoire n’est que de 5 %, soit une chance sur 20. Cela signifie que la probabilité qu’un réel changement se soit produit dans la fréquence des accidents à cette intersection est de 97,9 %. Un niveau de confiance de 5 % est généralement reconnu comme une indication fiable de l’efficacité de la mesure corrective, mais même un niveau de 10 % peut être considéré comme un indice qu’un changement s’est déjà produit. |
GROUPE DE SITES AYANT REÇU UN MÊME TRAITEMENT
Dans le cas d’un ensemble de N sites ayant reçu le même traitement, le calcul de l’effet global est plus complexe, puisqu’il faut résoudre l’équation suivante pour k, en considérant tous les sites, c’est- à-dire pour i = 1 à N. Les autres symboles sont identiques à ceux utilisés dans les équations précédentes.

On utilise, pour ce test, le logarithme népérien de cette variable, dont la distribution est généralement plus symétrique (et donc compatible avec les traitements statistiques standards). L’écart-type de loge k peut être approximé à l’aide de l’équation suivante :

Le ratio suivant doit alors être calculé en utilisant le logarithme népérien (loge) de la valeur de k calculée ci-dessus, ainsi que son écart type issu de l'expression précédente :

Si cette valeur s’écarte des limites ±1,96 (test de Student), alors le changement est considéré comme statistiquement significatif (au niveau de confiance de 95 %).
Pour vérifier ensuite si les changements observés sur les sites traités produisent effectivement le même effet sur les fréquences d’accidents, il faut calculer la valeur du khi-deux suivante :

Si cette valeur est significative avec N-1 degrés de liberté (d’après la (N-1)ème ligne de la table du khi-deux, où N représente le nombre de sites traités), cela indique que les changements observés sur les sites ne produisent pas le même effet. Si au contraire elle n’est pas significative, il est probable que les changements produisent effectivement le même effet.
CALCULATEUR : TESTS AVANT-APRÈS (GROUPE DE SITES)
CORRECTION DE L’EFFET DE RÉGRESSION VERS LA MOYENNE
Pour corriger l’effet de la régression vers la moyenne, il est nécessaire d’estimer le niveau de sécurité (c’est-à-dire la fréquence moyenne d’accidents à long terme). Plusieurs statisticiens ont proposé des méthodes pour y parvenir. Ainsi, Hauer (1992) suggère de recourir aux méthodes empiriques bayésiennes pour estimer le niveau de sécurité d’un site, et d’utiliser ensuite cette estimation plutôt que les données brutes. Abbess et al. (1981) avaient auparavant décrit une méthode plus simple pour des sites individuels, permettant de corriger ce biais en se basant sur certaines hypothèses de distribution statistique des accidents sur une période de plusieurs années.
Il convient de recueillir des données d’accidents sur des sites présentant des caractéristiques similaires à celles du site traité, pour des périodes identiques. À partir de cet ensemble de données, il est alors possible de calculer la fréquence moyenne d’accidents, a, et la variance des accidents, var (a). L’équation suivante permet de calculer l’effet de la régression vers la moyenne R (en %) :

où :
A = nombre d’accidents sur le site ;
n = nombre d’années.

At et nt sont les estimations des paramètres de la distribution statistique représentant les fréquences réelles sous-jacentes des accidents, c’est-à-dire la distribution de probabilité de la fréquence d’accidents avant l’obtention des données. L'hypothèse principale est donc que le site étudié, avec un historique particulier d'accidents, se comportera de la même manière qu’un ensemble des sites similaires présentant un historique comparable.
Exemple Soit une intersection où il s’est produit en moyenne 15 accidents par an sur une période de 5 ans. L’intersection a été élargie, une nouvelle signalisation avec arrêts a été installée, ainsi que des îlots séparateurs. Après ces travaux, on y a enregistré en moyenne 10 accidents par an sur une période de temps similaire. Pour corriger l'effet de régression vers la moyenne, il convient de sélectionner les intersections non contrôlées similaires, présentant des flux de trafic similaires. Si l’ensemble de ces sites affiche une moyenne annuelle a de 12,6 accidents, avec une variance var(a) de 2,91, les valeurs à utiliser sont : a = 12,6 accidents/an var(a) = 2,91 (accidents/an)2 A = 75 accidents/5 ans n = 5 ans At = 12,62 / (2,91 – 12,6) = –16,38 nt = 12,6 / (2,91 – 12,6) = –1,3 L’effet de la régression vers la moyenne est donc : En d’autres termes, on aurait pu s’attendre à une diminution de 5,6 % des accidents sur le site durant la période « après », même en l’absence d’intervention, soit une fréquence de 14,16 accidents par an. C’est cette valeur de 14,16 accidents par an qu’il faut comparer aux 10 accidents effectivement observés, pour déterminer si la réduction de la fréquence d’accidents, attribuable aux améliorations apportées, est statistiquement significative ou non. |